General
Discriminative Model
- learn decision boundaries between classes
- SVM, Logistic Regression, Decision Trees
- Not great w outliers
- Maximizes conditional likelihood, given model parameters
- \(L(\theta)=\max{P(y | x;\ \theta)}\)
Generative Model
- Distribution of classes themselves
- Naïve Bayes, Discriminant Analysis (LDA, GDA)
- Better with outliers
- Maximizes joint likelihood: the joint probability given model
parameters
- \(L(\theta)=\max{P(x, y;\ \theta)}\)
Cross Validation
- Typically use k-fold validation: i.e. leave one out cross validation
- Roll forward Cross Validation: used with Time Series Data
Tree Pruning
- Mitigate Overfitting
Cost Effective Pruning:
- Remove a subtree (replacing with a leaf node)
- if resulting tree does not have a significant decrease in performance (delta formula) then keep the new pruned tree and repeat.
Ensemble learning
- Boosting, Bagging, Random Forest
- Aggregation mitigates overfitting of a class
Bagging
- Train several models and vote to produce output.
Boosting
- Use a model to improve performance where another model is weakest. (i.e. model the error)
Fourier Transform
- Decompose functions into its constituent parts.
Logistic Regression
- Regression for classification.
- Linear model produces logits, softmax(logits) produces prediction
Model Evaluation
ROC
- Receiver Operator Characteristic
- Graphs Sensitivity vs Specificity (OR Precision)
- i.e. True Positive vs True Negative Rates
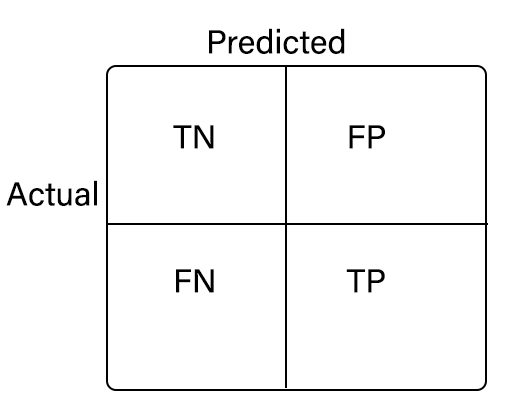
Accuracy
True predictions/Number points
Precision
\(\text{precision}=TP/(TP+FP)\)
- How many of our positive predictions were right?
- Positive Prediction Accuracy for the label
- Proportion of positive results that were correctly classified
- \(\text{precision}=\text{true\_pos}/(\text{true\_pos} + \text{true\_neg})\)
- Good if we have an imbalance such as way more negatives than positives (not in eq)
Sensitivity/Recall
\begin{align} \text{sensitivity}&=TP/(TP+FN)\ &=\text{true_pos}/(\text{true_pos} + \text{false_neg}) \end{align}
- Calcualtes the True Positive Rate of the label.
Specificity
\[
\text{specificity}=\text{TN}/(\text{TN} + \text{FP})
\]
AUC
- Area Under the Curve
- Used to compare ROC curves
- More AUC=better
Neural Networks
RNN
- Handle sequential data (unlike feedforward nn).
- Sentiment analysis, text mining, image captioning, time series problems
CNNs
- Image matrix, filter matrix
- Slide filter matrix over the image acompute the dot product to get convolved feature matrix.
- CNN better than Dense NN for Images: Because less params (no overfit), more interpretable (can look at weights), CNNs can learn simple-to-complex patterns (learn complex patterns by learning several simple patterns)
GANs
- Use a Generator and Discriminator (to build an accurate Discriminator model)
Activation Functions
- Softmax
- Scales input to (0,1). Output layers
- ReLU
- Clips input at 0, only non-negative outputs.
- Produces "rectified feature map." Hidden layers
- Swish
- Variant of ReLU developed at google, better at some DL tasks
Pooling
- Pooling is a down-sampling operation that reduces the dimensionality of the feature map
Computation Graph
- Nodes are operations, Edges are tensors/data
Batch Gradient vs Stochastic Gradient Descent
Autoencoder
- 3 Layer model that tries to reconstruct its input using a hidden layer of fewer dimensions to create a latent space representation.
- In its most basic form, uses dimensionality reduction to perform filtering (i.e. noise).
Regularized Autoencoders: Classification (include Sparse, Denoising, Contractive)
Variational Autoencoders: Generative models
Uses
- Extract features and hidden patterns
- Dimensionality reduction
- Denoise images
- Convert black and w hite images into colored images.
Transfer Learning
- Models: VGG-16, BERT, GPT-3, Inception, Xception
Vanishing Gradients
- Use ReLU instead of tanh (try different activation function)
- Try Xavier initialization (takes into account number of inputs and outputs).
ANN Hyperparameters
- Batch size: size of input data
- Epochs: number of times training data is visible to the neural network to train.
- Momentum: Dampen/attenuate oscillations in gradient descent. If the weights matrix is ill conditioned, this helps convergence speed up a bit.
- Learning rate: Represents the time required for the network to update the parameters and learn.
Dealing with Datasets
Imbalanced Datasets
- Random Under-sampling: Lots of data in smaller class
- Random Over-sampling: Not lots of data in smaller class
Missing Data:
- Imputation (i.e. 0), add a new category for categorical (I.e. "other"), interpolation
Outliers
- *Analyze without and without outliers
- Trimming: Remove outliers
- Winsorizing: Ceil/Floor to a max/min non-outlier value
SMOTE
- Synthetic Monetary Oversampling*
- Synthesize new data with minor noise added to existing sample rather than exact copies